Methodology
From prompt to confidence interval
in five steps
Every evaluation follows a rigorous statistical pipeline that transforms qualitative LLM responses into quantitative risk metrics.
Define your evaluation in YAML
Declare your prompt template, variable axes (categorical and continuous), oracle definitions, and compliance mappings in a single version-controlled file.
Declarative · Git-native · AuditableGenerate prompt variants
Latin Hypercube Sampling ensures efficient, comprehensive coverage of the parameter space — personas, temperatures, phrasings, and structures — testing your model the way real users will use it.
Latin Hypercube · Stratified · ReproducibleRun inference at scale
The full prompt ensemble is executed against your target LLM in batch, producing responses that capture the real distribution of model behavior.
Batch processing · Any LLM providerScore with dual oracles
Each response is evaluated twice: embedding similarity against a canonical answer measures accuracy, while an LLM-as-Judge evaluates explainability against your rubric. Two dimensions, two independent scores.
Cosine similarity · LLM-as-Judge · Binary labelsSynthesize Bayesian confidence
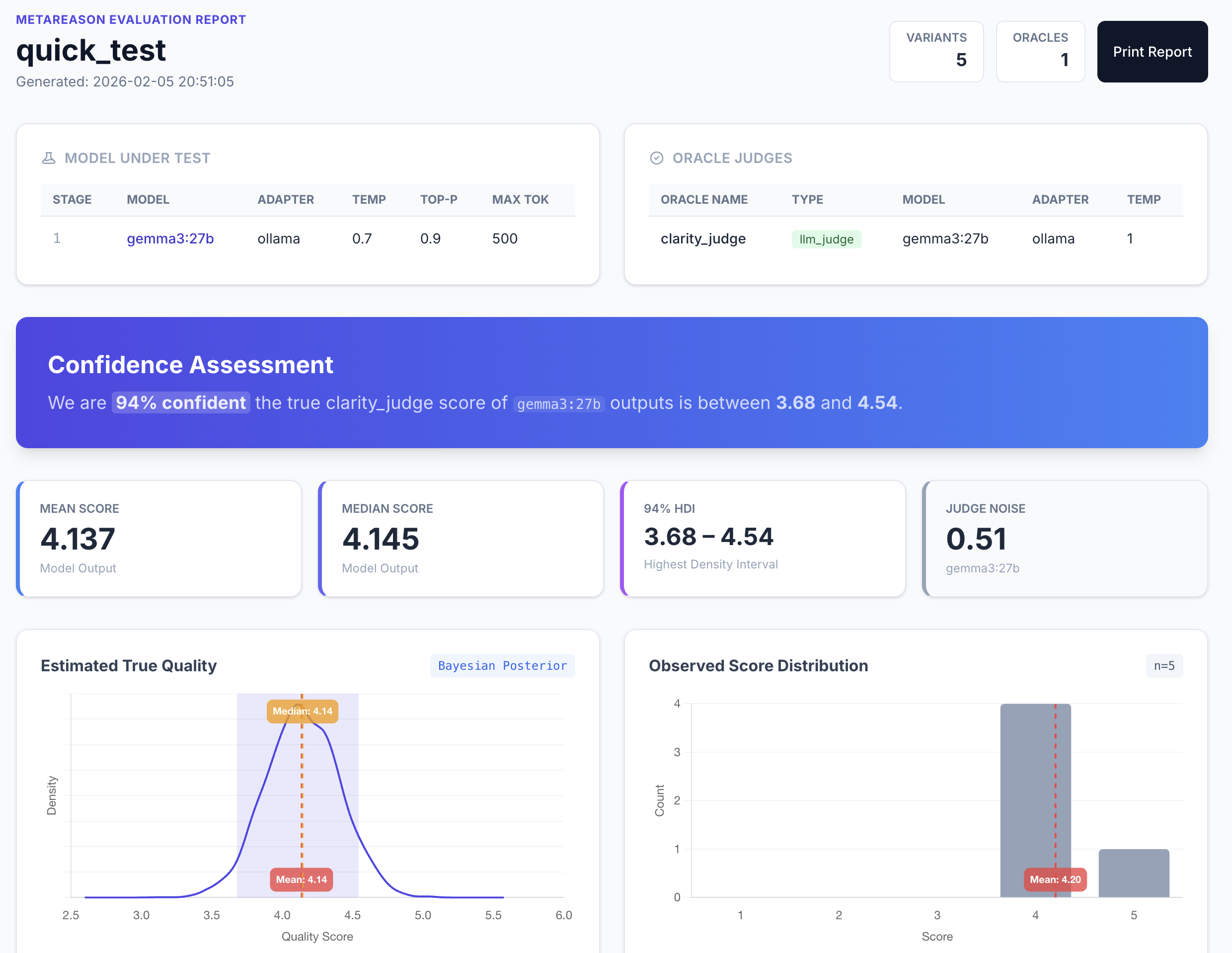
Binary labels feed into a PyMC Beta-Binomial model, producing full posterior distributions for P(accuracy) and P(explainability) with 95% Highest Density Intervals. Not point estimates — real confidence intervals.
PyMC · Beta-Binomial · 95% HDI